Cómo operamos una agencia AI-native: los 4 modos de IA

Cuando empezamos nothiring, ser AI-native no era una opción, era la única forma. Hasta ahora, el software era lo que mejor escalaba; las agencias tradicionales daban mucho valor pero escalar no era obvio. Esto está cambiando: la IA se está mejorando a sí misma a un ritmo que permite escalar una agencia casi como software.
“AI-native companies that don’t sell software — they sell the service. Instead of giving you a tool, they just do the work.” — YC request for startups, summer 2026
Las agencias no venden software como herramienta, venden el outcome directamente. Una agencia de recruiting no te ayuda a ser más rápido buscando — te entrega el perfil validado, listo para tu proceso. O por lo menos debería. Es lo que hacemos en nothiring.
Nuestra apuesta era — y sigue siendo — un equipo pequeño con muchísimo impacto, que escale con procesos e IA a full más que con personas. A día de hoy estamos más seguros que nunca. La IA está en todos lados y la usamos de muchas formas. Aunque cambia casi cada semana, hemos identificado 4 modos claros a nivel operativo:
Set the scene
Antes de entrar en el contenido, dos cosas importantes.
Esto va de operativa, no de producto. Es cómo usamos la IA para construir y operar nothiring, no la IA dentro de la plataforma (matching, embeddings, features para nuestros usuarios…). De eso ya hablaremos que da para rato también.
No tenemos tiempo infinito. Somos un par de co-founders construyendo un producto, captando usuarios, hablando con empresas y operando recruiting al mismo tiempo. No nos podemos permitir un proyecto interno de planificación y aplicación de IA. La integramos donde mejora un proceso concreto que ya estábamos haciendo. Si funciona se queda, si no, chao.
Nos dejamos muchos detalles en el tintero, la idea es dar una visión global. Ya iremos publicando detalles jugosos en nuevos posts.
Los 4 modos
| Modo | Para qué | Quién decide | Supervisión humana | Riesgo si falla |
|---|---|---|---|---|
| 1. Conversacional | Organizar info, contexto día a día | Humano pregunta, IA responde | Total — somos los ojos | Bajo |
| 2. Agentes autónomos | Procesos repetibles internos | IA decide cómo, humano define qué | Mínima — calificamos outputs | Medio |
| 3. Vibe coding | Software interno (ATS, dashboards) | IA escribe e implementa | Casi nula — sólo lo crítico | Medio |
| 4. AI-assisted coding | Producto público | Humano dirige, IA implementa | Alta — review en PR | Alto |
A partir de aquí, modo a modo.
Modo 1 — Conversacional
El más obvio y el que casi todo el mundo usa: hablar con un modelo a través de su app de escritorio. En nuestro caso Claude (Desktop, Code o Cowork), Gemini y a veces ChatGPT.
Lo que lo hace útil de verdad no es la conversación — son las conexiones. Nos conectamos a herramientas externas principalmente mediante MCPs. En algunos casos — mediante skills — también nos conectamos a APIs directamente, CLIs o incluso dejamos que la IA interaccione con el navegador directamente. No es tan robusto, pero funciona bastante bien.
Las herramientas que más utilizamos:
- Productividad: Gmail, Google Drive, Google Calendar, Slack, Granola, Attio…
- Interno: ATS (and more coming soon)
- Tech: Sentry, Cloudflare, Railway, PostHog…
Con esto, podemos hacer preguntas directas como: lee el último meeting con esta empresa, mira qué perfil estamos buscando en nuestro ATS, y dime qué candidatos de los que ya tenemos podrían encajar o dame la evolución de DAU de la plataforma. El modelo navega los datos reales, los relaciona, y nos devuelve algo accionable.
La supervisión es total, estamos continuamente hablando con la herramienta y la idea es que accionemos nosotros manualmente, pero el boost en productividad es brutal. Cada conversación es diferente, no hay un patrón.
Modo 2 — Agentes autónomos
Aquí saltamos de yo hablo con la IA a la IA ejecuta procesos por mí. El cambio mental es grande.
Hay muchos pequeños procesos — y estamos continuamente añadiendo más —, pero nuestro ejemplo principal es sourcing. Esto nos ayuda a encontrar candidatos de forma más eficiente:
- Definimos un objetivo y un flujo de alto nivel (dada esta job description, encuentra perfiles que cumplan X, prioriza Y, intégralo con Z).
- El agente recibe varias fuentes de datos como input.
- A partir de ahí decide. Escribe sus propios scripts, llama a servicios externos, hace benchmarking, va relacionando información, y nos pregunta cuando necesita una calificación humana. Itera e itera y se automejora.
Estos agentes empiezan con un CLAUDE.md y skills que describen el objetivo y el proceso de cómo queremos que se haga a alto nivel. Sabiendo su objetivo, los agentes van creando su tooling interno y scripts de código que van necesitando para conseguirlo. El sistema se autogestiona — incluso decide a veces dónde guardar datos intermedios, qué APIs llamar, cuándo paralelizar. Lo más importante es el qué y no tanto el cómo a bajo nivel (script en Python o JavaScript? whatever.).
Esto lo hacemos todo en Claude Code desde la terminal, todo en local. En algunos casos le pedimos que nos genere una aplicación web para tener una UI más interactiva, pero el cerebro sigue siendo Claude Code corriendo en terminal.
Aquí la supervisión humana es bastante baja, hay que dedicarle más tiempo al principio para crear y afinar el proceso. Luego durante la operativa normal es simplemente contestar cuando el agente nos pide alguna acción, como puede ser: calibra estos candidatos o quieres que haga una nueva búsqueda o parto de esta búsqueda anterior?. Va bastante en autopilot.
Show me the money. Un ejemplo de la mejora de productividad: antes podíamos seleccionar 40 perfiles para contactar en todo un día — dado que teníamos que hacer muchas otras cosas y esto era una tarea síncrona. Ahora en menos de 15 minutos dedicados podemos tener el triple de candidatos validados.
Lo que nos hemos dado cuenta es que hay que afinar bien el proceso y cada vez que vemos un drift o un comportamiento que no nos gusta — en la mayoría de los casos porque no lo hemos especificado — indicarle al agente claramente cómo queremos que lo haga y que actualice la skill.
Este tipo de agentes es como contarle a alguien cómo queremos que haga un proceso, y lo hace. Es como si tuviéramos un workflow por debajo pero cogido con pinzas. Como software engineer, lo que más me choca es que no es determinista como software tradicional. Es como que tiene una guía y hace cosas en esa dirección — sorprendentemente bien y como yo lo haría la mayor parte del tiempo — pero el outcome no es determinista y pueden pasar cosas inesperadas. Cuanto más acotado es el problema y el proceso, mejor, aunque no podemos evitar que invente algunas veces o tome atajos cuando el course of action no es obvio o no está totalmente definido.
No te convence o no tienes claro cómo hacerlo? Hazte otro. Hasta hace poco, Sergio y yo teníamos cada uno un agente haciendo lo mismo pero adaptado a nuestro flujo y con approaches diferentes. Both worked. El coste es prácticamente nulo.
Lo importante: si tuviéramos que pararnos a desarrollar software a mano — o incluso con IA — para resolver estos workflows, no lo haríamos. El coste de oportunidad sería demasiado grande. Pero ahora, hacerlo no es una opción, es una obligación.
Tenemos bastantes más cosas de automatización rodando, pero eso lo contamos en otro episodio 😁
Modo 3 — Vibe coding
Antes de seguir, una distinción que confunde a mucha gente: cuál es la diferencia entre el modo 2 y el modo 3 si en ambos la IA tiene libertad y no revisamos el código?
La diferencia es qué persiste. El modo 2 produce outputs — listas de candidatos, datos enriquecidos, acciones ejecutadas. Los scripts intermedios pueden ser temporales o cambiar on-the-fly. El modo 3 produce software — código real para aplicaciones que son desplegadas y están siempre disponibles — en nuestro caso una aplicación web. El artefacto es el código, no el resultado de ejecutarlo una vez.
Eso cambia las decisiones de diseño. En el modo 2 te importa el resultado más que otra cosa. En el modo 3 importa que el software haga lo que esperamos y sea determinista.
Qué hacemos vibe-codeando?
Simplificando, la idea del vibecoding es producir código hablando lenguaje natural, sin escribir código manualmente. En muchos casos, el código nos da igual, lo que queremos es software que haga algo.
Si fueran para usuarios finales, la calidad del código importaría más. Para uso interno, lo que manda es resolver el pain.
Tenemos varias apps internas vibe-codeadas. Dashboards de métricas, monitor de competencia… Cualquier aplicación que es — o podría — ser útil para nosotros internamente y queremos testear, lo vibecodeamos. Si no es útil en unos días, la eliminamos. Actualmente la más importante es nuestro ATS interno.
Al principio de nothiring, empezamos con el ATS en Google Sheets, como casi todo el mundo doing things that don’t scale. Funciona hasta que deja de funcionar o la lógica de negocio se convierte en un bottleneck, entonces te planteas si pagar por un ATS de fuera y tirarte tiempo adaptándolo a tu flujo, y otro tiempo hablando con el equipo de ventas para que haga esa integración o feature que es clave para ti, o te lo montas tú. Como software engineer te lo puedes programar for fun, como founder te lo vibecodeas por necesidad. Este ATS tiene el flujo adaptado perfectamente a nuestro flujo de trabajo y cuando necesitamos algo, le tiramos un prompt y que se lo haga Claude. Flipas lo fino que va.
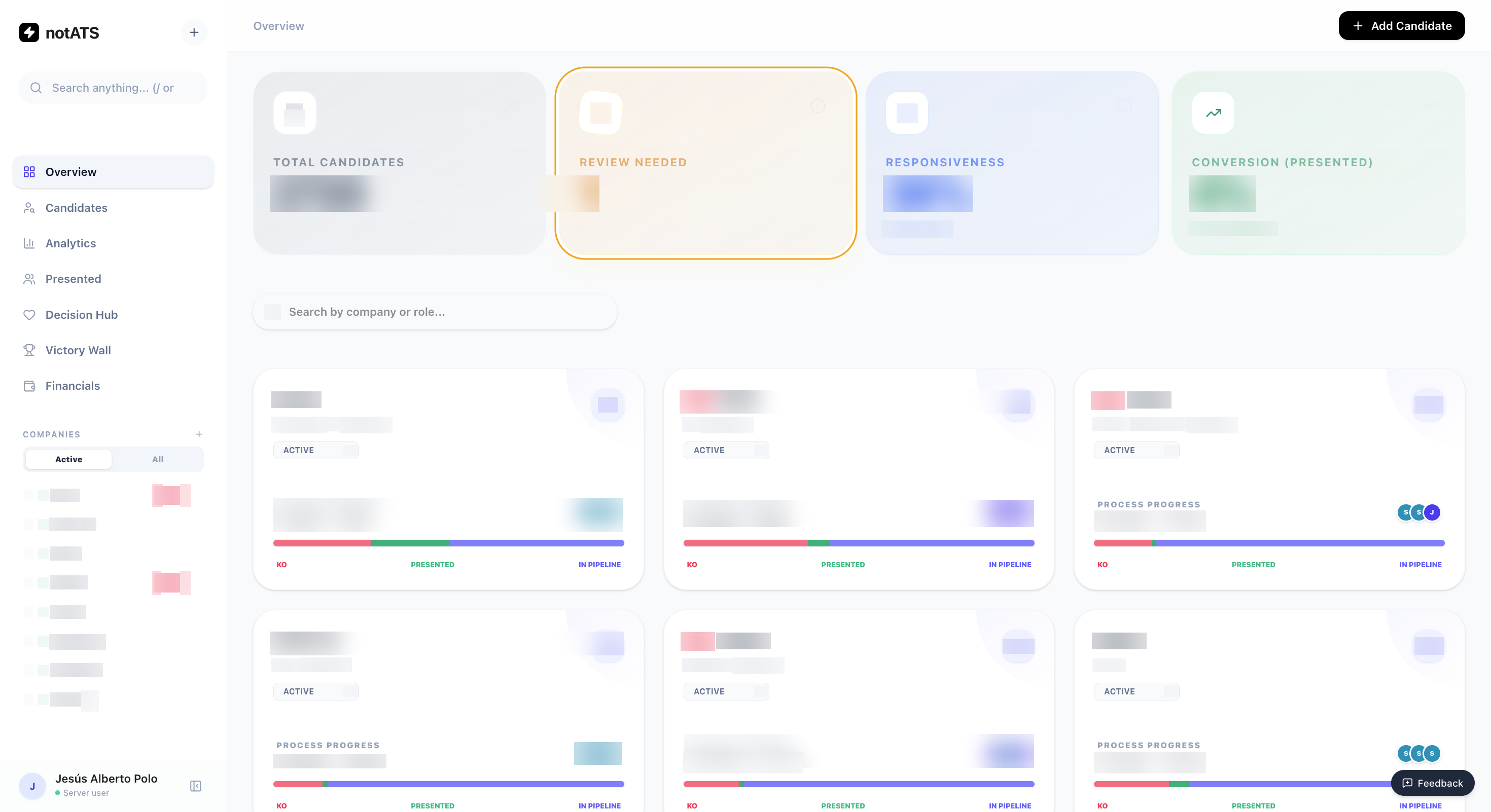
Lo mejor no es simplemente tener tu ATS, sino que además la interfaz se adapte a cada usuario. A Sergio le gusta la información de una forma, y a mí de otra, pues literal tenemos interfaces fluidas que se adaptan a cada usuario a lo que mejor le va en cada momento. Tenemos un software con muchas versiones por encima, prácticamente de gratis y con opciones infinitas. Imagina pedirle eso a quien te vende un ATS rígido, a día de hoy no he visto que lo ofrezcan — y es normal.
A nivel de desarrollo, aunque todo pasa por GitHub, ignoramos bastante el código a no ser que sea un cambio grande o una migración de base de datos. Lo más importante — y arriesgado — de tener nuestro propio ATS no es el software, sino los datos. Una mala migración que corrompe la base de datos no es nada fun y puede impactar a la operativa significativamente.
Para los más techies, tenemos una app NextJS desplegada en Railway con una base de datos en GCP. Esta app expone un MCP que podemos consumir desde otros agentes (hello modo 1, modo 2 👋). Closing the loop, innit.
Y qué pasa con la seguridad? Vibecodeamos sin mirar el código, pero no somos tontos — tenemos datos reales de gente real. Es vibecoding con guardarrailes: lo crítico lo miramos a mano, los agentes auditan la seguridad de endpoints en cada feature, y todo lo interno está detrás de Cloudflare Access, sólo el founding team puede entrar. Si algo se rompe el blast radius somos nosotros. All good.
Modo 4 — AI-assisted coding
Este es el opuesto del modo 3. Nuestros usuarios interactúan con la plataforma de nothiring y es crítico para nosotros. Aquí no hacemos vibe coding, aquí revisamos código.
Hace más de un año empezamos programando la plataforma principalmente a mano, usando IA de forma menos intrusiva: autocompletado de código y discusión sobre el diseño del software. En los últimos meses el flujo ha cambiado completamente, ya que absolutamente todo el código lo escribe la IA hoy en día.
Para cambios pequeños: prompt corto, Claude Code lo implementa, verificamos, PR. Suele ser un par de prompts, todo muy rápido con feedback loop instantáneo.
Para cambios grandes: el flujo es más estructurado.
- Damos contexto largo, normalmente por voz. Mucho contexto. También le pasamos enlaces a documentación relevante.
- Le pedimos que analice el prompt antes de hacer nada, busque clarificaciones, trade-offs y proponga un plan con edge cases.
- Iteramos sobre el plan hasta que cubra todas las bases que tanto nosotros como la IA creemos relevantes.
- Le decimos que implemente. Solemos lanzar subagentes en paralelo (frontend / backend / tests) cuando tiene sentido, para cambios ultra tochos incluso paralelizamos con worktrees — así tenemos diferentes sub-flujos y PRs.
- La PR se crea automáticamente.
- Revisamos PR, añadimos comentarios, le decimos a Claude que los lea e implemente (si es necesario nos preguntará clarificaciones) y volvemos a revisar PR.
- All good? Merge PR. Deploy automático, enjoy 😎
En las PR sí miramos el código. Generalmente no línea a línea, pero en diagonal con atención y haciendo foco en puntos clave como migraciones de bases de datos o API endpoint definitions. Nos importa cómo está construido, qué patrones se introducen, si encaja con el resto de la codebase. Mucho que decir aquí, pero nuestra máxima es que el código sea mantenible y la IA no freestylee — el efecto cascada puede ser muy peligroso, entre otros. Como están avanzando las cosas este proceso cambiará en los próximos meses, pero de momento es como más cómodos nos sentimos.
Nota: hay equipos que están utilizando agentes que hagan code reviews automáticos en local o en PRs. Lo podríamos meter, pero a la velocidad y volumen al que vamos no interesa todavía.
Puntos más críticos
Hay ciertas partes que miramos con más detalle por el impacto y efecto bola de nieve que pueden tener:
- Migraciones de base de datos en producción.
- Auth flows y manejo de sesiones.
- Infra stuff.
- Cualquier gestión de PII de usuarios.
- Tests de integración, nuestro acceptance criteria.
Tenemos una estrategia de tests de integración muy agresiva desde el principio, y eso nos ha ayudado mucho a apalancarnos en la IA para escribir código, hacer refactoring y meter nuevas features con pocos dolores de cabeza.
Para los más techies, la plataforma es una API en Go y un frontend (con BFF) en NextJS, ambos desplegados en Railway. También usamos Cloudflare Durable Objects — btw Durable Objects are underrated — para la parte realtime como chat, notas compartidas y notificaciones en vivo. Elegir el stack adecuado y estar familiarizados con él también nos ha dado una velocidad de desarrollo brutal.
Takeaways
Llevamos varios meses iterando este modelo, y cada semana más 😁. Cuantas más iteraciones hacemos, una cosa nos queda cada vez más clara:
Todo es producto, trátalo como tal.
Sean agentes, vibecoded o AI-assisted-coded apps, todo son productos. Define, itera y piensa en ello como producto. Prueba, experimenta, implementa un feedback loop lo más cerrado posible y sigue construyendo. El qué es lo que importa, el cómo no tanto — y cada vez menos.
Y no todo merece la misma atención.
Una aplicación interna puede no tener la mejor UI o tener fallos de vez en cuando, el boost de productividad lo compensa. Pero cuando la aplicación la utilizan tus usuarios, quizás quieras tener más cuidado — o no 😅. Por ejemplo, tenemos y revisamos muchísimos tests para la plataforma, pero para las aplicaciones internas dejamos que se escriban automáticamente, who cares? Move fast and break things aplica a todo, aunque cuando es interno mucho más.
Lo bueno de la IA es que se adapta a cada proceso y forma de pensar. Nos encantaría conocer tu modelo.
Hiring? Nothiring. Live at nothiring.